Participamos de um Webinar há algumas semanas atrás com o Luiz Ferreira onde batemos um papo de 1 hora sobre desafios na parte da segurança defensiva.
Assistam lá e espero que gostem!
Lembrando que em breve lançaremos nossa grade de treinamentos defensivos para esse segundo semestre com tópicos como:
- ATT&CK
- Endpoint Monitoring
- Logging & Security Analytics
- Network Security Monitoring
- Threat Hunting
Acompanhem no twitter @BlueOpsBR e em nosso site https://www.blueops.com.br
Happy Detection!
Blue Team Operations
sexta-feira, 20 de julho de 2018
sexta-feira, 6 de julho de 2018
Measuring Operational Risks using Mitre {ATT&CK,Navigator} and Elastic Stack
First of all, we know that we should write in Portuguese, but this blogpost deserves to fly abroad Terra Brasilis, so we are opening an exception.
ATT&CK Introduction (retrieved from mitre attack website)




With data ingested in our Elasticsearch we created some views:


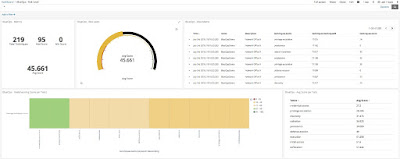
To download Kibana stuff https://github.com/spookerlabs/kibana_attack
Some ideas we have in mind for the future:
ATT&CK Introduction (retrieved from mitre attack website)
"Adversarial Tactics, Techniques, and Common Knowledge (ATT&CK™) for Enterprise is an adversary model and framework for describing the actions an adversary may take to compromise and operate within an enterprise network. The model can be used to better characterize and describe post-compromise adversary behavior. It both expands the knowledge of network defenders and assists in prioritizing network defense by detailing the tactics, techniques, and procedures (TTPs) cyber threats use to gain access and execute their objectives while operating inside a network.
ATT&CK for Enterprise incorporates information on cyber adversaries gathered through MITRE research, as well as from other disciplines such as penetration testing and red teaming to establish a collection of knowledge characterizing the activities adversaries use against enterprise networks. While there is significant research on initial exploitation and use of perimeter defenses, there is a gap in central knowledge of adversary process after initial access has been gained. ATT&CK for Enterprise focuses on TTPs adversaries use to make decisions, expand access, and execute their objectives. It aims to describe an adversary's steps at a high enough level to be applied widely across platforms, but still maintain enough details to be technically useful.
The 11 tactic categories within ATT&CK for Enterprise were derived from the later stages (exploit, control, maintain, and execute) of a seven-stage Cyber Attack Lifecycle[1] (first articulated by Lockheed Martin as the Cyber Kill Chain®[2]). This provides a deeper level of granularity in describing what can occur during an intrusion.
Each category contains a list of techniques that an adversary could use to perform that tactic. Techniques are broken down to provide a technical description, indicators, useful defensive sensor data, detection analytics, and potential mitigations. Applying intrusion data to the model then helps focus defense on the commonly used techniques across groups of activity and helps identify gaps in security. Defenders and decision makers can use the information in ATT&CK for Enterprise for various purposes, not just as a checklist of specific adversarial techniques.
ATT&CK for Enterprise incorporates details from multiple operating system platforms commonly found within enterprise networks, including Microsoft Windows, macOS, and Linux. The framework and higher level categories may also be applied to other platforms and environments. To view the contents of ATT&CK for Enterprise, use the left navigation pane, which breaks out techniques by tactic category or view All Techniques."
Based on ATT&CK we can take a snapshot of our company security state on each tactic and technique, knowing where we have better detection and where we should invest more efforts. So in our mind and talking about this during a ATT&CK training we were teaching, the question was how to create a visualization for this and decide quickly how to prioritize an IDS alert, or a vulnerability found or new technology we need to deploy to cover gaps ? The answer that we found was using Navigator Scoring with Elastic Stack.
ATT&CK for Enterprise incorporates information on cyber adversaries gathered through MITRE research, as well as from other disciplines such as penetration testing and red teaming to establish a collection of knowledge characterizing the activities adversaries use against enterprise networks. While there is significant research on initial exploitation and use of perimeter defenses, there is a gap in central knowledge of adversary process after initial access has been gained. ATT&CK for Enterprise focuses on TTPs adversaries use to make decisions, expand access, and execute their objectives. It aims to describe an adversary's steps at a high enough level to be applied widely across platforms, but still maintain enough details to be technically useful.
The 11 tactic categories within ATT&CK for Enterprise were derived from the later stages (exploit, control, maintain, and execute) of a seven-stage Cyber Attack Lifecycle[1] (first articulated by Lockheed Martin as the Cyber Kill Chain®[2]). This provides a deeper level of granularity in describing what can occur during an intrusion.
Each category contains a list of techniques that an adversary could use to perform that tactic. Techniques are broken down to provide a technical description, indicators, useful defensive sensor data, detection analytics, and potential mitigations. Applying intrusion data to the model then helps focus defense on the commonly used techniques across groups of activity and helps identify gaps in security. Defenders and decision makers can use the information in ATT&CK for Enterprise for various purposes, not just as a checklist of specific adversarial techniques.
ATT&CK for Enterprise incorporates details from multiple operating system platforms commonly found within enterprise networks, including Microsoft Windows, macOS, and Linux. The framework and higher level categories may also be applied to other platforms and environments. To view the contents of ATT&CK for Enterprise, use the left navigation pane, which breaks out techniques by tactic category or view All Techniques."
Based on ATT&CK we can take a snapshot of our company security state on each tactic and technique, knowing where we have better detection and where we should invest more efforts. So in our mind and talking about this during a ATT&CK training we were teaching, the question was how to create a visualization for this and decide quickly how to prioritize an IDS alert, or a vulnerability found or new technology we need to deploy to cover gaps ? The answer that we found was using Navigator Scoring with Elastic Stack.
So how we could do that with them?
Basically Mitre Navigator you can fill techniques with some Score based on tools you have or initially just based on "feelings". After you filled all the techniques you will have something like this:

We really suggest you split into minor areas, network segmentation, department this but in a very first step have a general one is a good start.
So having this read you have how to add Layer Name and Description (In our sample we configure Layer as "Company" and Description as "Network Segment")
After filling your matrix, you can download it as a JSON file. The only problem with JSON I found it was that logstash JSON filter can't parse it directly you I just remove newlines with some basic bash.
Regular JSON download

File ready, time to parse and send it to Elasticsearch. We just created a basic config to create this PoC that we have ideas to enrich with more information in a second part.
Config:
input {stdin {}}
filter {
json { source => message }
split {
field => "techniques"
}
mutate { remove_field => [ "gradient", "filters", "hideDisabled", "tacticRowBackground", "legendItems", "sorting","showTacticRowBackground", "viewMode", "selectTechniquesAcrossTactics","version" , "@version" , "[techniques][color]", "[techniques][enabled]", "message"] }
}
output {elasticsearch { index => navigator }}
Debug Output:

With data ingested in our Elasticsearch we created some views:


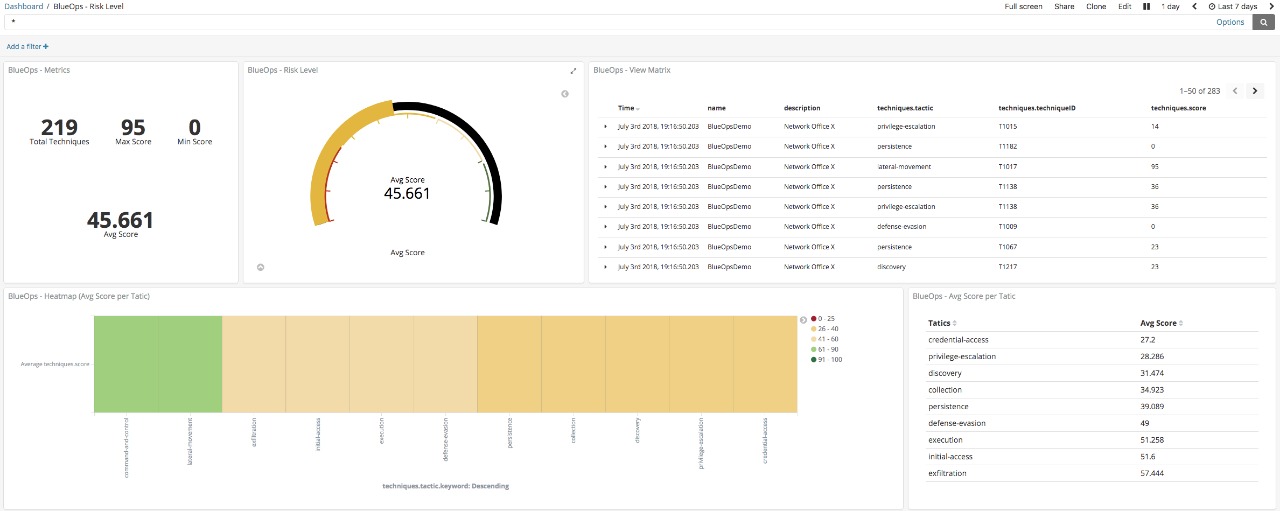
To download Kibana stuff https://github.com/spookerlabs/kibana_attack
Some ideas we have in mind for the future:
- Create a database about defense tools mapped with ATT&CK and correlate your status and needs
- Tool to quickly correlate a Pentest/VA report and prioritize vulnerability affects more your network
- Compare you security risk with groups or something you read and map.
- Integrate / Compatibility with HELK project
- Enrich information using translate at logstash
- Auto update scoring using Red Team automation / tests
- Add ATT&CK Pre
If you have something in mind let us know. Hope it helps!
Happy Detection!
Blue Team Operations
- Enrich information using translate at logstash
- Auto update scoring using Red Team automation / tests
- Add ATT&CK Pre
If you have something in mind let us know. Hope it helps!
Happy Detection!
Blue Team Operations
quarta-feira, 20 de junho de 2018
Fazendo tracking do login usuário e comandos no seu endpoint Linux com Audit e Elastic Stack
Já vimos no post anterior uma visão básica do Audit e seu potencial. Uma pergunta que sempre escuto é como monitorar todos comandos que são utilizados pelos usuários que acessam servidores ou até mesmo dos desktops com linux. Pensando nisso fizemos um laboratório rápido para ilustrar como é possível criar essa auditora rapidamente utilizando como base o CentOS.
Por padrão o audit linux já vem habilitado no CentOS, porém sem regras adicionadas. O primeiro ponto então é que regras devemos utilizar para ter esse controle. Sem pensar muito (logicamente com muito mais que precisamos pra isso , porém mais visibilidade ainda) indico o trabalho do Florian Roth que concatenou várias regras e sugestões num gist público
 Link: https://gist.github.com/Neo23x0/9fe88c0c5979e017a389b90fd19ddfee
Link: https://gist.github.com/Neo23x0/9fe88c0c5979e017a389b90fd19ddfee
Em resumo você precisa copiar esse conteúdo para o /etc/audit/conf.d/audit.rules e reinicar o serviço do auditd. Lembre-se de confirmar que as regras entraram em ação com o auditctl -l.
Com isso criado, basicamente configurei meu logstash para parsear as informações, deixando ela BEM granulizada pois assim conseguimos filtrar e criar visualizações para tudo que necessitarmos. Os eventos do audit possuem dezenas de campos e para minha felicidade postaram um guia com todos os campos e explicações de cada que vocês podem aprender e entender melhor acessando :
 Link: https://github.com/bfuzzy/Linux-Audit-Events/blob/master/Linux_Audit_Event_Fields.md
Link: https://github.com/bfuzzy/Linux-Audit-Events/blob/master/Linux_Audit_Event_Fields.md
Após o entendimento e evento sendo salvos na stack elastic, o que precisamos ter em mente é o que queremos. No meu exemplo quero saber:
- Usuário origem
- IP Origem
- Comandos digitados
Com essa pergunta em mente, basicamente o que preciso é pegar o tipo USER_LOGIN, da onde se é gerado um campo chamado ses que é carregado para o tipo SYSCALL e consequentemente analisarei o tipo PROCTITLE que terá o comando digitado.
A tela inicial de evento salvos podem ser visto aqui:

 Após isso, para adiantar minhas análises criei algumas visualizações que mostrarei na sequência para um drilldown
Após isso, para adiantar minhas análises criei algumas visualizações que mostrarei na sequência para um drilldown

Nessa visualização pegaremos o audit_ses (436) e usaremos de filtro
Para facilitar o processo, criamos um script onde eu colocando a sessão eu mapeio todos os comandos da sessão de forma rápida e via linha de comando.
 Além de uso para monitorar usuários, um ponto legal também é para Honeypots de alta interatividade.
Além de uso para monitorar usuários, um ponto legal também é para Honeypots de alta interatividade.
Agora para ficar melhor a visualização, temos o vídeo com todo processo
No próximo post, compartilharemos a config do Logstash bem como o script em python para maior rapidez na resposta a análises necessárias.
Aproveitando, se quiser aprender mais sobre logging com elastic, entender eventos entre outros assuntos importantes no lado defensivo não deixe de fazer nosso treinamento https://blueops.com.br/treinamento/gerencia-logs/
Happy Detection!
Equipe Blue Ops
Por padrão o audit linux já vem habilitado no CentOS, porém sem regras adicionadas. O primeiro ponto então é que regras devemos utilizar para ter esse controle. Sem pensar muito (logicamente com muito mais que precisamos pra isso , porém mais visibilidade ainda) indico o trabalho do Florian Roth que concatenou várias regras e sugestões num gist público

Em resumo você precisa copiar esse conteúdo para o /etc/audit/conf.d/audit.rules e reinicar o serviço do auditd. Lembre-se de confirmar que as regras entraram em ação com o auditctl -l.
Com isso criado, basicamente configurei meu logstash para parsear as informações, deixando ela BEM granulizada pois assim conseguimos filtrar e criar visualizações para tudo que necessitarmos. Os eventos do audit possuem dezenas de campos e para minha felicidade postaram um guia com todos os campos e explicações de cada que vocês podem aprender e entender melhor acessando :

Após o entendimento e evento sendo salvos na stack elastic, o que precisamos ter em mente é o que queremos. No meu exemplo quero saber:
- Usuário origem
- IP Origem
- Comandos digitados
Com essa pergunta em mente, basicamente o que preciso é pegar o tipo USER_LOGIN, da onde se é gerado um campo chamado ses que é carregado para o tipo SYSCALL e consequentemente analisarei o tipo PROCTITLE que terá o comando digitado.
A tela inicial de evento salvos podem ser visto aqui:



Nessa visualização pegaremos o audit_ses (436) e usaremos de filtro
Para facilitar o processo, criamos um script onde eu colocando a sessão eu mapeio todos os comandos da sessão de forma rápida e via linha de comando.

Agora para ficar melhor a visualização, temos o vídeo com todo processo
No próximo post, compartilharemos a config do Logstash bem como o script em python para maior rapidez na resposta a análises necessárias.
Aproveitando, se quiser aprender mais sobre logging com elastic, entender eventos entre outros assuntos importantes no lado defensivo não deixe de fazer nosso treinamento https://blueops.com.br/treinamento/gerencia-logs/
Happy Detection!
Equipe Blue Ops
quarta-feira, 6 de junho de 2018
Introdução ao monitoramento de endpoint Linux com o audit
Um dos pontos críticos que temos na área defensiva é justamente saber o que acontece na máquina, seja de forma regular ou maliciosa, mas alguma forma de fazer o tracking da origem conexão, usuário, ações executadas entre outros pontos. Existe em praticamente todo Sistema Operacional algum sistema de auditoria escutando por isso, muitas vezes apenas esperando ser habilitado ou configurado.
No caso do Linux temos o Audit, que por padrão no CentOS vem instalado e habilitado, porém sem regras. O Audit do linux podemos monitorar tudo que acontece no sistema baseado nas 330+ syscall existentes.
A arquitetura do audit basicamente é representada nessa imagem:

Você tem aplicações, processos, comandos sendo executados no userland e "comunicando com o kernel", sendo que o audit pega essas infos diretamente lá e joga de volta para o sistema no userland.
A estrutura do audit instalado no SO é a seguinte:
Configurações => /etc/audit/
Regras => /etc/audit/rules.d/
Eventos => /var/log/audit/
Existe alguns comandos para ver quais as configurações existente, pesquisar eventos gerados e relatórios
auditctl
ausearch
aureport
Para simularmos algo simples, criarei uma regra para monitorar arquivos binários que por simulação considero suspeito que seriam whoami e tcpdump
Inicialmente sem regras:
Repetindo os comandos acima (não colando novamente para não alongar o post)
O audit é extremamente poderoso e possui uma granularidade muito interessante nas informações que geram. Em próximas postagens falaremos mais específico sobre regras e campos, integração com Stack Elastic, osquery e alguns casos de monitoramento.
Link excelente documentação da Redhat: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/6/html/security_guide/chap-system_auditing
Happy Hunting!
Equipe BlueOps
No caso do Linux temos o Audit, que por padrão no CentOS vem instalado e habilitado, porém sem regras. O Audit do linux podemos monitorar tudo que acontece no sistema baseado nas 330+ syscall existentes.
A arquitetura do audit basicamente é representada nessa imagem:

Você tem aplicações, processos, comandos sendo executados no userland e "comunicando com o kernel", sendo que o audit pega essas infos diretamente lá e joga de volta para o sistema no userland.
A estrutura do audit instalado no SO é a seguinte:
Configurações => /etc/audit/
Regras => /etc/audit/rules.d/
Eventos => /var/log/audit/
Existe alguns comandos para ver quais as configurações existente, pesquisar eventos gerados e relatórios
auditctl
ausearch
aureport
Para simularmos algo simples, criarei uma regra para monitorar arquivos binários que por simulação considero suspeito que seriam whoami e tcpdump
Inicialmente sem regras:
[root@BlueOpsLabs rules.d]# ausearch -i -k blueopsdemo
<no matches>
[root@BlueOpsLabs rules.d]# tcpdump -c1
<REMOVED>
1 packet captured
7 packets received by filter
0 packets dropped by kernel
[root@BlueOpsLabs rules.d]# whoami
root
[root@BlueOpsLabs rules.d]# ausearch -i -k blueopsdemo
<no matches>
[root@BlueOpsLabs rules.d]#
Após os testes, podemos ver que nada foi gerado. Para gerar, precisamos de regras e aqui criei 2regras básicas monitorando o caminho binário -w e quando a permissão execução entrar em ação -x p e salvando com a key blueopsdemo
[root@BlueOpsLabs rules.d]# cat blueops.rules
-w /usr/sbin/tcpdump -p x -k blueopsdemo
-w /usr/bin/whoami -p x -k blueopsdemo
[root@BlueOpsLabs rules.d]#
Restart e regras adicionadas
[root@BlueOpsLabs rules.d]# service auditd restart
Stopping logging: [ OK ]
Redirecting start to /bin/systemctl start auditd.service
[root@BlueOpsLabs rules.d]# ausearch -i -k blueopsdemo
----
type=CONFIG_CHANGE msg=audit(06-06-2018 15:12:41.294:55348) :
auid=unset ses=unset subj=system_u:system_r:unconfined_service_t:s0
op=add_rule key=blueopsdemo list=exit res=yes
----
type=CONFIG_CHANGE msg=audit(06-06-2018 15:12:41.295:55350) :
auid=unset ses=unset subj=system_u:system_r:unconfined_service_t:s0
op=add_rule key=blueopsdemo list=exit res=yes
[root@BlueOpsLabs rules.d]#
Repetindo os comandos acima (não colando novamente para não alongar o post)
----
type=PROCTITLE msg=audit(06-06-2018 15:14:22.393:55352) :
proctitle=tcpdump -c1
type=PATH msg=audit(06-06-2018 15:14:22.393:55352) :
item=1 name=/lib64/ld-linux-x86-64.so.2 inode=87703 dev=fd:01 mode=file,755
ouid=root ogid=root rdev=00:00 obj=system_u:object_r:ld_so_t:s0
objtype=NORMAL cap_fp=none cap_fi=none cap_fe=0 cap_fver=0
type=PATH msg=audit(06-06-2018 15:14:22.393:55352) :
item=0 name=/usr/sbin/tcpdump inode=543204 dev=fd:01 mode=file,755
ouid=root ogid=root rdev=00:00 obj=system_u:object_r:netutils_exec_t:s0
objtype=NORMAL cap_fp=none cap_fi=none cap_fe=0 cap_fver=0
type=CWD msg=audit(06-06-2018 15:14:22.393:55352) :
cwd=/etc/audit/rules.d
type=EXECVE msg=audit(06-06-2018 15:14:22.393:55352) :
argc=2 a0=tcpdump a1=-c1
type=SYSCALL msg=audit(06-06-2018 15:14:22.393:55352) :
arch=x86_64 syscall=execve success=yes exit=0 a0=0x19ea8e0
a1=0x19eae90 a2=0x19bde70 a3=0x7ffdd8102e60 items=2 ppid=887
pid=5481 auid=root uid=root gid=root euid=root suid=root
fsuid=root egid=root sgid=root fsgid=root tty=pts1 ses=105
comm=tcpdump exe=/usr/sbin/tcpdump
subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 key=blueopsdemo
----
type=PROCTITLE msg=audit(06-06-2018 15:14:30.373:55355) :
proctitle=whoami
type=PATH msg=audit(06-06-2018 15:14:30.373:55355) :
item=1 name=/lib64/ld-linux-x86-64.so.2 inode=87703 dev=fd:01
mode=file,755 ouid=root ogid=root rdev=00:00
obj=system_u:object_r:ld_so_t:s0 objtype=NORMAL
cap_fp=none cap_fi=none cap_fe=0 cap_fver=0
type=PATH msg=audit(06-06-2018 15:14:30.373:55355) :
item=0 name=/usr/bin/whoami inode=12611372 dev=fd:01
mode=file,755 ouid=root ogid=root rdev=00:00
obj=system_u:object_r:bin_t:s0 objtype=NORMAL
cap_fp=none cap_fi=none cap_fe=0 cap_fver=0
type=CWD msg=audit(06-06-2018 15:14:30.373:55355) :
cwd=/etc/audit/rules.d
type=EXECVE msg=audit(06-06-2018 15:14:30.373:55355) :
argc=1 a0=whoami
type=SYSCALL msg=audit(06-06-2018 15:14:30.373:55355) :
arch=x86_64 syscall=execve success=yes exit=0
a0=0x19eaab0 a1=0x19e0540 a2=0x19bde70
a3=0x7ffdd8102e60 items=2 ppid=887 pid=5482
auid=root uid=root gid=root euid=root suid=root fsuid=root
egid=root sgid=root fsgid=root tty=pts1 ses=105
comm=whoami exe=/usr/bin/whoami
subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
key=blueopsdemo
----
Link excelente documentação da Redhat: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/6/html/security_guide/chap-system_auditing
Happy Hunting!
Equipe BlueOps
segunda-feira, 14 de maio de 2018
Analyzing apps table with osquery - Something weird with GotoMeeting

We were doing some test and queries using Facebook osquery to create some packs and noticed something not common when analyzing apps table.
osquery> SELECT name, bundle_short_version, bundle_version, bundle_identifier FROM apps WHERE name LIKE '%gotomeeting%';
+------------------------+----------------------+----------------+-------------------------+
| name | bundle_short_version | bundle_version | bundle_identifier |
+------------------------+----------------------+----------------+-------------------------+
| GoToMeeting.app | 8.24.0.8569 | 8569 | com.logmein.GoToMeeting |
| GoToMeeting (8404).app | 8.21.0.8404 | 8404 | com.logmein.GoToMeeting |
| GoToMeeting (8473).app | 8.22.0.8473 | 8473 | com.logmein.GoToMeeting |
| GoToMeeting (8557).app | 8.23.0.8557 | 8557 | com.logmein.GoToMeeting |
| GoToMeeting (8569).app | 8.24.0.8569 | 8569 | com.logmein.GoToMeeting |
| GoToMeeting (8625).app | 8.25.0.8625 | 8625 | com.logmein.GoToMeeting |
| GoToMeeting (8679).app | 8.26.0.8679 | 8679 | com.logmein.GoToMeeting |
| GoToMeeting (8789).app | 8.27.0.8789 | 8789 | com.logmein.GoToMeeting |
+------------------------+----------------------+----------------+-------------------------+
osquery>
As you can see, multiples version of GotoMeeting were found. Analyzing a bit we noticed that main GotoMeeting application was pointing to an old version (in red) and not current one (in green).
osquery> SELECT name, bundle_short_version, bundle_version, bundle_identifier FROM apps WHERE name LIKE '%gotomeeting%';
+------------------------+----------------------+----------------+-------------------------+
| name | bundle_short_version | bundle_version | bundle_identifier |
+------------------------+----------------------+----------------+-------------------------+
| GoToMeeting.app | 8.24.0.8569 | 8569 | com.logmein.GoToMeeting |
| GoToMeeting (8404).app | 8.21.0.8404 | 8404 | com.logmein.GoToMeeting |
| GoToMeeting (8473).app | 8.22.0.8473 | 8473 | com.logmein.GoToMeeting |
| GoToMeeting (8557).app | 8.23.0.8557 | 8557 | com.logmein.GoToMeeting |
| GoToMeeting (8569).app | 8.24.0.8569 | 8569 | com.logmein.GoToMeeting |
| GoToMeeting (8625).app | 8.25.0.8625 | 8625 | com.logmein.GoToMeeting |
| GoToMeeting (8679).app | 8.26.0.8679 | 8679 | com.logmein.GoToMeeting |
| GoToMeeting (8789).app | 8.27.0.8789 | 8789 | com.logmein.GoToMeeting |
+------------------------+----------------------+----------------+-------------------------+
osquery>
If you look into Mac Applications we have:

Clicking to open GotoMeeting it'll open version 8.24.

Some questions:
- Is something wrong in my Mac or it's a real problem ? (hope so , because if it isn't, this is a huge attack surface)
- Why main Application is not pointing to correct version ?
- Why they keep all old binaries version ?
Could someone test and validate more ? I didn't have another Mac to validate this or with GotoMeeting installed since very long time ago.
Happy Hunting.
BlueOps Team
Assinar:
Comentários (Atom)